Deploying models into production is a complex affair
The biggest issue in the life-cycle of ML project isn’t to create a good algorithm or to generalize the results or to get good predictions or better accuracy. The biggest issue is to put ML systems into production. One of the known truth of Machine Learning world is that only a small part of real-world ML system is composed of ML code and a big part is model deployment, model retraining, maintenance, on-going updates and experiments, auditing, versioning and monitoring. And these steps take a huge part in ML systems technical debt as it exists at the system/platform level rather than the code/development level. Hence the model deployment strategy becomes a very crucial step in designing the ML platform.
Introduction
The first step in determining how to deploy a model is understanding the system with these questions-
- how end user interacts with the model’s predictions.
- how frequently you should generate predictions.
- whether predictions should be generated for a single instance or a batch of instances at a time.
- what is the number of applications that will access this model.
- what is the latency requirements of these applications
It’s indicative of the complexity of machine learning systems that many large technology companies who depend heavily on machine learning have dedicated teams and platforms that focus on building, training, deploying and maintaining ML models. Here are some examples:
- Databricks has MLFlow
- Google has TensorFlow Extended (TFX)
- Uber has Michelangelo
- Facebook has FBLearner Flow
- Microsoft has AI Lab
- Amazon has Amazon ML
- AirBnb has BigHead
- JPMC has Omni AI
Machine Learning System vs Traditional Software System
1. Unlike Traditional Software Systems, ML systems deployment isn’t same as deploying a trained ML model as service. ML systems requires multi-step automated deployment pipeline for retraining, validation and deployment of model — which adds complexity.
2. Testing a ML system involves model validation, model training etc — in addition to the software tests such as unit testing and integration testing.
3. Machine Learning Systems are much more dynamic in terms of performance of the system due to varying data profiles and the model has to be retrained/refreshed often which leads to more iterations in the pipeline. This is not the case with Traditional Software Systems.
Model Portability (From Model Development to Production)
Writing code to predict/score data, is most often done in Jupyter notebooks or an IDE. Taking this model development code to production environment requires to convert language specific code to some exchange format (compressed & serialized) that is language neutral and lightweight. Hence portability of model is also a key requirement.
Below are the widely use formats for ML model portability-
1. Pickle — The pickle file is the binary version of Python object which is used for serializing and de-serializing a Python object structure. Conversion of a Python object hierarchy into a byte stream is called “Pickling”. When a byte stream is converted back to object hierarchy, this operation is called “unpickling”.
2. ONNX (Open Neural Network Exchange) — ONNX is an open source format for machine learning models. ONNX has a common set of operators and a file format to use with models on a variety of frameworks and tools.
3. PMML (The Predictive Model Markup Language) — PMML is an XML-based predictive model interchange format. With PMML, you can develop a model on one system on an application and deploy the model on another system with another application, only by transmitting an XML configuration file.
4. PFA (Portable Format for Analytics) — PFA is an emerging standard for statistical models and data transformation engines. PFA has the ease of portability across systems and models, pre-processing, and post-processing functions can be chained and built into complex workflows. PFA can be a raw data transformation or a sophisticated suite of concurrent data mining models, with a JSON or YAML configuration file.
5. NNEF (Neural Network Exchange Format) — NNEF is useful in reducing the pains in machine learning deployment process by enabling a rich mix of neural network training tools for applications to be used across a range of devices and platforms.
There are some framework specific formats as well, like — Spark MLWritable (Spark specific) and POJO / MOJO (H2O.ai specific).
CI/CD in Machine Learning
In traditional software systems, Continuous Integration & Delivery has been the approach to bring automation, quality, and discipline to create a reliable, predictable and repeatable process to release software into production. The same should be applied to ML Systems? Yes, but the process is not simple. The reason is in case of ML systems, changes to ML models and the data used for training also needs to be managed along with the code into the ML delivery process.

So unlike traditional DevOps, MLOps has 2 more steps every time CI/CD runs.
Continuous integration in machine learning means that each time you update your code or data, the machine learning pipeline reruns, which kickoff builds and test cases. If all the tests are successful then Continuous Deployment begins that deploy the changes to the environment.
Within ML System, there is one more term for MLOps called CT (Continuous Training) which comes into picture if you need to automate the training process.
Although the market has some reliable tools for ML Ops and new tools are also coming up, its still new to predict the ML model outcome in the production environment.
New tools like, Gradient and MLflow are becoming popular for building a robust CI/CD pipelines in ML systems. Tools such as Quilt, Pachyderm are leading the way for a forward-looking data science/ML workflows but they have not yet had widespread adoption. Some other alternatives include dat, DVC and gitLFS; but the space is still new and relatively unexplored.
Deployment Strategies
There are many different approaches when it comes to deploying machine learning models into production and an entire book could be written on this topic. In fact, I am not sure if it exists already. The choice of deployment strategy depends totally on the business requirement and how we plan to consume the output prediction. On a very high level, it can be categorized as below-
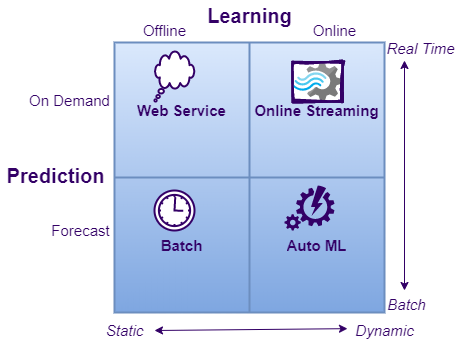
Batch Prediction
Batch Prediction is the simplest form of machine learning deployment strategy which is used in online competitions and academics. In this strategy you schedule the predictions to run at a particular time and outputs them to database / file systems.
Implementation
Below approaches can be used to implement batch predictions-
- Simplest way is to write a program in Python and schedule it using Cron, but it requires extra effort to introduce functionalities for validating, auditing and monitoring. However, now days we have many tool/approaches that can make this task simpler.
- Writing a Spark Batch job and schedule it in yarn and introduce logging for monitoring and retry functionalities.
- Using tools like Perfect and Airflow which provides UI capabilities for scheduling, monitoring and alert notifications in case of failures.
- Platforms like Kubeflow, MLFlow and Amazon Sagemaker also provide batch deployment and scheduling capabilities.
Web Service
The most common and widely used machine learning deployment strategy is a simple web service. It is easy to build and deploy. The web service takes input parameters and outputs the model predictions. The predictions are almost real-time and doesn’t require lots of resources also as it will predict one record at a time, unlike batch prediction that processes all the records at once.
Implementation
- To implement the predictions as web service, the simplest way is to write a service and put it in a docker container to integrate with existing products. Though this is not the sexiest solution but probably the cheapest.
- The most common framework to implement ML model as a service is using Flask. You can then deploy your flask application on Heroku or Azure or AWS or Google Cloud or just deploy using PythonAnywhere.
- Another common way to implement ML model as service is using Django app and deploy it using Heroku/AWS/Azure/Google Cloud platforms.
- There are few new options like Falcon, Starlette, Sanic, FastAPI and Tornado also talking space in this area. FastAPI along with Uvicorn server is becoming famous these days because of minimal code requirements and it automatically creates both OpenAPI (Swagger) and ReDoc documentation.
Why Online/Real-Time Predictions?
Above two approaches are widely used and almost 90% of the time you will be using either of two strategies to build and deploy your ML pipelines. However, there are few concerns with both of these approaches-
1. Performance tuning of bulk size for batch partitioning.
2. Service exhaustion, Client starvation, Handling failures and retries are common issues with web services. If model calls are asynchronous, this approach fails to trigger back pressure in case there is a burst of data such as during restarts. This can lead to Out of Memory failures in the model servers.
The answer to the above issues lies in next two approaches.
Real-Time Streaming Analytics
From last few years, the world of software has moved from Restful services to the Streaming APIs, so should the world of ML.
Hence another ML workflow that’s emerging now days is real-time streaming analytics, which is also known as Hot Path Analytics.
In this approach, the requests to the model/data load comes as stream (commonly as Kafka stream) of events, the model is placed right in the firehose, to run on the data as it enters the system. This creates a system that is asynchronous, fault tolerant, replayable and is highly scalable.
The ML system in this approach is event-driven and hence it allows us to gain better model computing performance.
Implementation
- To implement ML system using this strategy, the most common way is to use Apache Spark or Apache Flink (both provide Python API). Both allows for easy integration of ML models written using Scikit-Learn or Tensorflow other than Spark MLlib or Flink ML.
- If you are not comfortable with python or if there is already an existing data pipeline which is written in Java or Scala, then you can use Tensorflow Java API or third-party libraries such as MLeap or JPMML.
Automated Machine Learning
If we just train a model once and never touch it again, we’re missing out the information more/new data could provide us.
This is especially important in environments where behaviors change quickly, so you need ML model that can learn from new examples in something closer to real time.
With Automated ML, you should both predict and learn in real time.
A lot of engineering is involved in building ML model that learns online, but the most important factor is architecture/deployment of model. As model can, and will, change every second, you can’t instantiate several instances. Also it’s not horizontally scalable and you are forced to have a single model instance that eats new data as fast as it can, spitting out sets of learned parameters behind an API. The most important part in the process (the model) is only vertically scalable. It may not even be feasible to distribute between threads.
Real-time examples of this strategy are — Uber Eats delivery estimation, LinkedIn’s connections suggestions, Airbnb’s search engines, augmented reality, virtual reality, human-computer interfaces, self-driving cars.
Implementation
- Sklearn library has few algorithms that support online incremental learning using partial_fit method, like SGDClassifier, SGDRegressor, MultinomialNB, MiniBatchKMeans, MiniBatchDictionaryLearning.
- Spark MLlib doesn’t have much support for online learning and has 2 ML algorithms to support online learning – StreamingLinearRegressionWithSGD and StreamingKMeans.
- Creme also has good APIs for online learning.
Challenges
Online training also has some issues associated with it. As data is changing often your ML model can be sensitive to the new data and change its behavior. Hence a mandatory on the fly monitoring is required and if the change threshold is more than a certain percentage; then data behavior has to be managed properly.
For example in any recommendation engine, if one user is liking or disliking a category of data in bulk; then this behavior, if not taken care properly can influence the results for other users. Also chances are that this data can be a scam, so it should be removed from the training data.
Taking care of these issues/patterns in batch training is relatively easy and the misleading data patterns and outliers can be removed from training data very easily. But in Online learning its much harder, and creating a monitoring pipeline for such data behavior can be a big hit on performance as well due to the size of training data.
Other Variants in Deployment Strategies
There are few other variants in deployment strategies, like adhoc predictions via SQL, model server (RPCs) and embedded model deployments, tiered storage without any Data Storage, Database as a model storage. All these are combination / variants of above four strategies. Each strategy itself is a chapter, so its beyond the scope of this article. But the essence is that deployment strategies can be combined / molded as per the business need. For example, if data is changing frequently but you do not have the platform / environment to do online learning, then you can do batch learning (every hour/day, depending on need) parallel to the online prediction.
Monitoring ML Model Performance
Once a model is deployed and running successfully into production environment, it is necessary to monitor how well the model is performing. Monitoring should be designed to provide early warnings to the myriad of things that can go wrong in a production environment.
Model Drift
Model Drift is described as the change in the predictive power of ML model. In a dynamic data system where new data is being acquired very regularly, the data can change significantly over a short period of time. Therefore the data that we used to train the model in the research or production environment does not represent the data that we actually get in our live system.
Model Staleness
If we use historic data to train the models, we need to anticipate that the population, consumer behavior, economy and its effects may not be the same in current times. So the features that were used to train the model will also change.
Negative Feedback Loops
One of the key features of live ML systems is that they tend to influence their own behavior when they update over time which may lead to a form of analysis debt, This in turn make it difficult to predict the behavior of a ML model before it is released into the system. These feedback loops are difficult to detect and address specially if they occur gradually over time, which may be the case when models are not updated frequently.
To avoid/treat above issues in the Production system, there needs to be a process that measures the model’s performance against new data. If the model falls below an acceptable performance threshold, then a new process has be initiated to retrain the model with new/updated data, and that newly trained model should be deployed.
Conclusion
At the end, there is no generic strategy that fits every problem and every organization. Deciding what practices to use, and implementing them, is at the heart of what machine learning engineering is all about.
You will often see when starting with any ML project; the primary focus is given on the data and ML algorithms, but looking at how much of work is involved in deciding ML infrastructure and deployment, focus should be given to these factors as well.
Thanks for the read. I hope you liked the article!! As always, please reach out for any questions / comments / feedback